

Anthropic has a new answer for the headache every engineering team using its tools is starting to feel: too much code, too fast, and not enough eyes to catch what breaks.
On Monday, the company rolled out Code Review inside Claude Code, a multi-agent system that automatically scrutinizes every pull request and surfaces bugs before human reviewers even open the diff. It’s available now in research preview for Teams and Enterprise customers, with a simple GitHub App install that lets admins flip it on for any repository.
The problem it targets is one Anthropic helped create. Claude Code, the agentic coding environment the company launched earlier this year , has supercharged developer output. Internally at Anthropic, code produced per engineer jumped 200 percent over the past year. Pull requests multiplied. Traditional code review, the last line of defense against logic errors, security holes, and subtle regressions, became the bottleneck. “We’ve seen a lot of growth in Claude Code, especially within the enterprise,” Cat Wu, Anthropic’s head of product, told TechCrunch. “One of the questions that we keep getting from enterprise leaders is: Now that Claude Code is putting up a bunch of pull requests, how do I make sure that those get reviewed in an efficient manner?” Her answer: “Code Review is our answer to that.”
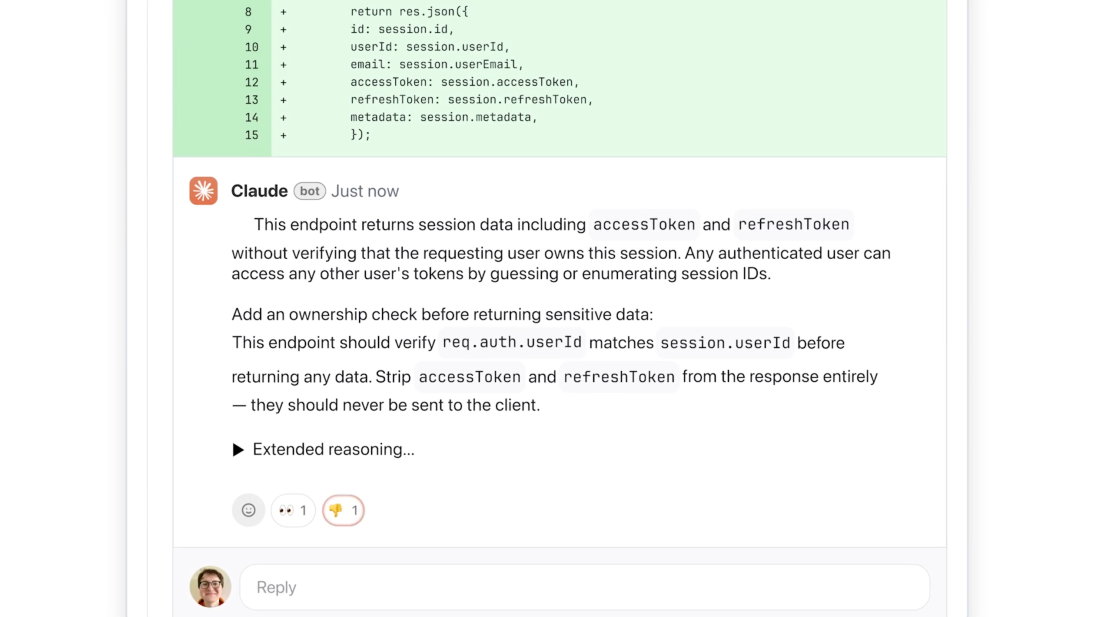
Here’s how it actually works. When a PR lands, Code Review spins up a team of specialized agents that attack the change from different angles, in parallel. They hunt for bugs, cross-check one another’s findings to kill false positives, then rank what’s left by severity. The final output is deliberately high-signal: one overview comment at the top of the PR plus targeted inline notes. Each finding explains the issue, why it matters, and a suggested fix. Color-coded labels help at a glance, red for critical, yellow for worth a look, purple for problems tied to preexisting code.
The system is explicitly tuned for depth, not speed. Average review time clocks in around 20 minutes. Trivial PRs get a light pass; sprawling changes trigger more agents and deeper context. It deliberately ignores style nits and bikeshedding, zeroing in on logic errors, the kind that ship to production and wake someone up at 3 a.m. “We decided we’re going to focus purely on logic errors,” Wu said. “This way we’re catching the highest priority things to fix.”
The numbers from Anthropic’s own internal deployment are telling. Before Code Review, only 16 percent of PRs received substantive human comments. After, that figure climbed to 54 percent, not because humans suddenly had more time, but because the AI surfaced issues worth their attention. On large PRs (more than 1,000 lines changed), 84 percent now generate findings, averaging 7.5 issues each. Even on tiny PRs under 50 lines, 31 percent get flagged. Engineers agree with the AI’s take more than 99 percent of the time.
Real examples make the case better than any benchmark. In one internal incident, a seemingly harmless one-line change to a production service looked routine, the kind of diff that normally sails through with a quick LGTM. Code Review flagged it as critical: the tweak would have broken authentication for the entire service. The engineer later admitted they would have missed it. In another case, during a ZFS encryption refactor in TrueNAS’s open-source middleware, the tool spotted a latent type-mismatch bug in adjacent code that was silently wiping the encryption key cache on every sync, a pre-existing landmine the PR merely brushed against.
Pricing reflects the ambition. Reviews are billed by token usage and average $15 to $25 each, scaling with complexity. That’s not cheap, and Anthropic doesn’t pretend otherwise. Spokespeople have framed it as “insurance” for code quality rather than a productivity hack. The lighter-weight Claude Code GitHub Action remains free and open source for teams that want basic AI feedback. Code Review is the premium, thorough option for organizations shipping to production.
The timing is no accident. Claude Code’s run-rate revenue has already topped $2.5 billion, and enterprise subscriptions have quadrupled since the start of the year. Customers such as Uber, Salesforce, and Accenture are leaning hard into the platform. But with that adoption comes new friction: the very speed that excites leadership is overwhelming review queues. Code Review is Anthropic’s attempt to close the loop, to turn AI-assisted coding from a force multiplier into a sustainable workflow.
It also marks a subtle but important evolution in the company’s strategy. Anthropic isn’t just selling frontier models anymore. It’s shipping opinionated developer infrastructure on top of them. The same multi-agent approach that powers Code Review echoes the internal practices the company now feels confident enough to productize. Other AI coding assistants have focused on generation; Anthropic is doubling down on verification and governance.
Of course, no automated reviewer replaces human judgment. Code Review doesn’t approve or merge anything, that remains a human call. What it does is shrink the review surface area so engineers can focus on architecture, trade-offs, and product decisions instead of hunting for off-by-one errors in 2,000-line diffs.
For teams already drowning in AI-generated pull requests, the appeal is obvious. For the broader industry, the launch underscores a maturing reality: the era of “vibe coding” has arrived, and the tools that win won’t just write code faster, they’ll help organizations trust what they ship. Anthropic is betting enterprises will pay real money for that trust. Early signs suggest the bet is landing.



